在这篇文章中,我们将实践通过Ollama在本地计算机部署阿里大模型Qwen2.5,并通过命令行和API的方式进行调用。
Ollama的出现简化了大模型中本地部署的过程,让我们可以很轻松的将网络上的开源模型在本地计算机中运行。
Qwen2.5是由阿里推出的大语言模型,参数规模从5亿到720亿不等,支持超过29种语言。
一、安装Ollama并部署Qwen2.5
Ollama的安装非常简单,前往官网下载安装包直接安装就可以,支持的操作系统包括Windows、Linux、macOS。
这里以在Windows系统上安装为例。
运行安装程序后点击“Install”按钮就可开始安装。
安装完成后在命令行中执行ollama --version,如果正确出现版本号说明安装成功。
然后我们在Ollama模型库网站(https://ollama.com/library)检索需要的模型,搜索qwen2.5。
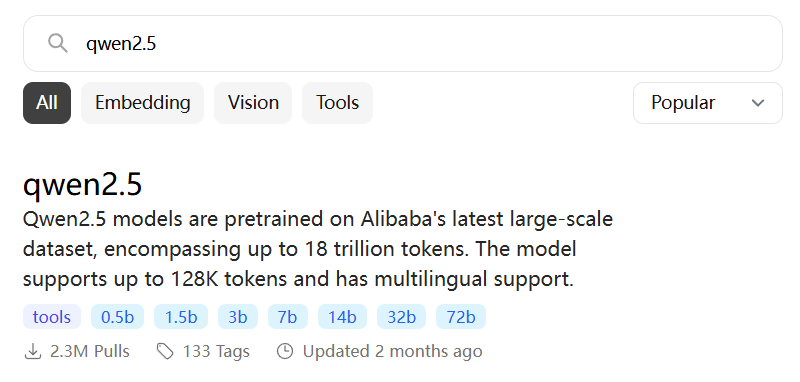
进入页面后可以看到Qwen2.5模型有好几种不同的参数规格,这里的B代表的是10亿个可训练参数,一般来说同种模型下规模大的比规模小的效果好,占用资源也越多。
这里以选择1.5B的模型为例,复制右侧的启动命令。
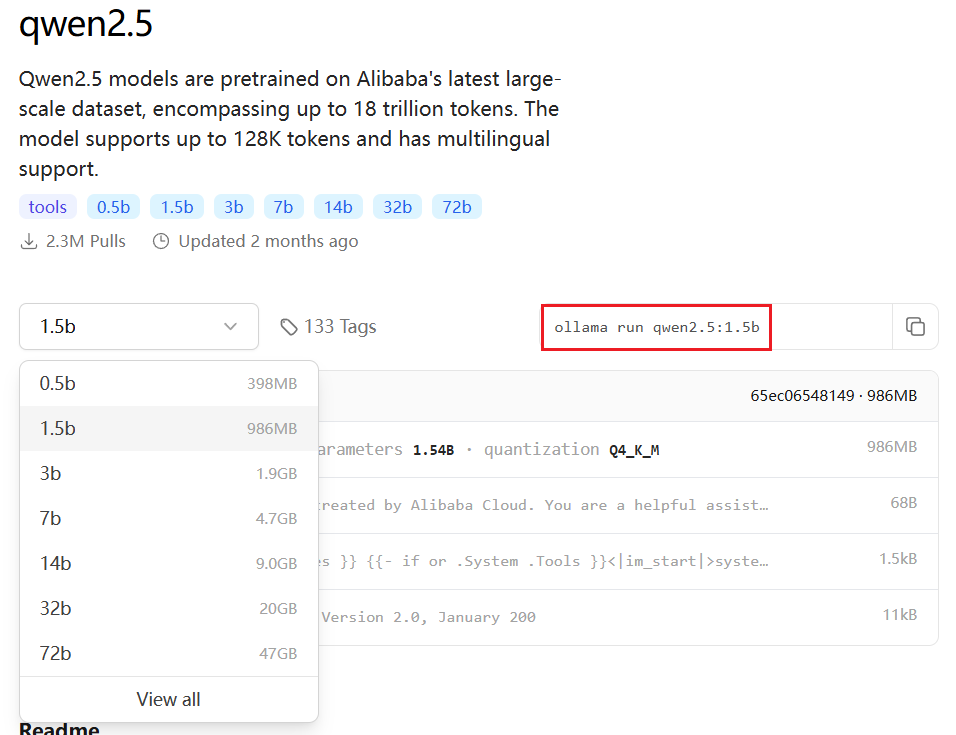
在命令行中执行复制的命令ollama run qwen2.5:1.5b,首次执行时Ollama会自动下载模型文件,下载完成后就可以与大模型对话了。

二、使用命令行管理模型
1.启动模型
执行命令 ollama run 模型名 就可以启动指定的模型。
例如:ollama run qwen2.5:1.5b
在与模型对话过程中输入/bye就可以结束对话。
2.列出已下载的模型
执行命令 ollama list 可以查询当前计算机中已下载的模型。

3.删除模型
执行命令 ollama rm 模型名 可以删除指定的模型。

三、通过API调用模型
Ollama会在11434端口启动API服务,我们可以通过HTTP请求的方式调用大模型,API文档可参考此处。
1.文本生成
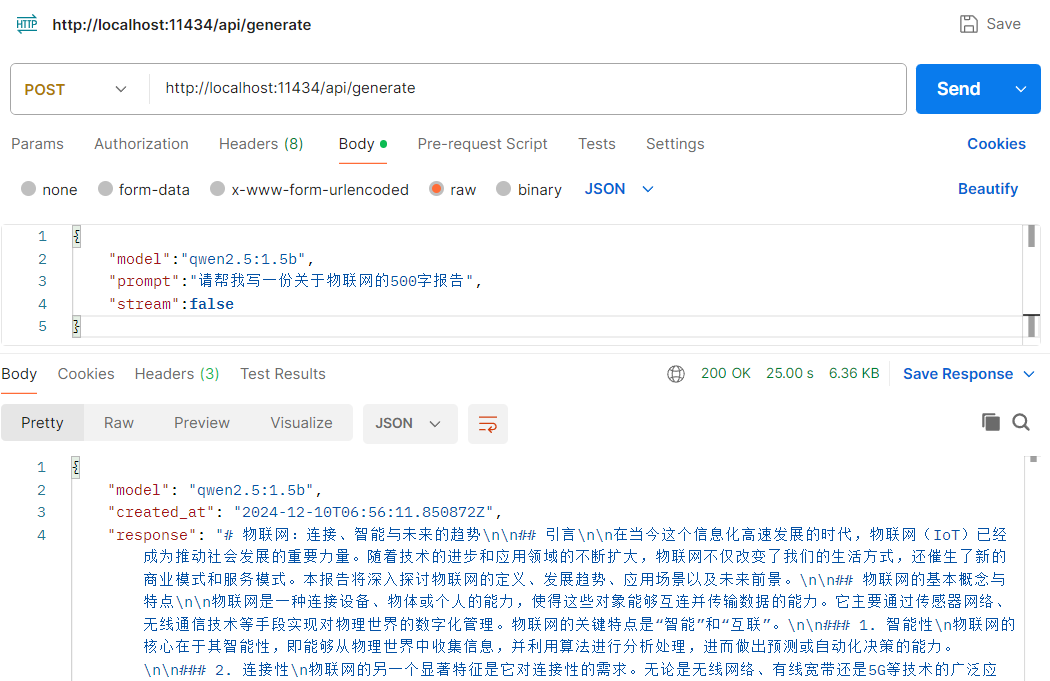
POST请求http://localhost:11434/api/generate,请求体如下:
{
"model":"qwen2.5:1.5b",
"prompt":"请帮我写一份关于物联网的500字报告",
"stream":false
}参数解释:
model:要调用的模型名称
prompt:提示词
stream:为false时禁用流式返回
2.聊天文本生成
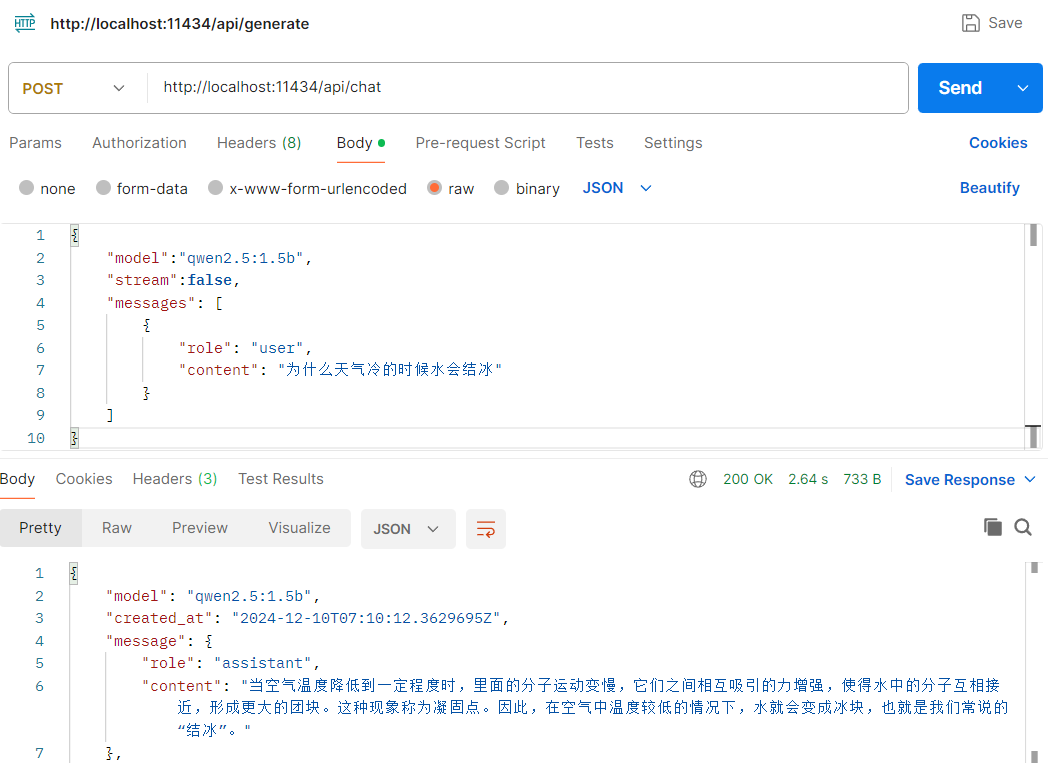
POST请求http://localhost:11434/api/chat,请求体如下:
{
"model":"qwen2.5:1.5b",
"stream":false,
"messages": [
{
"role": "user",
"content": "为什么天气冷的时候水会结冰"
}
]
}
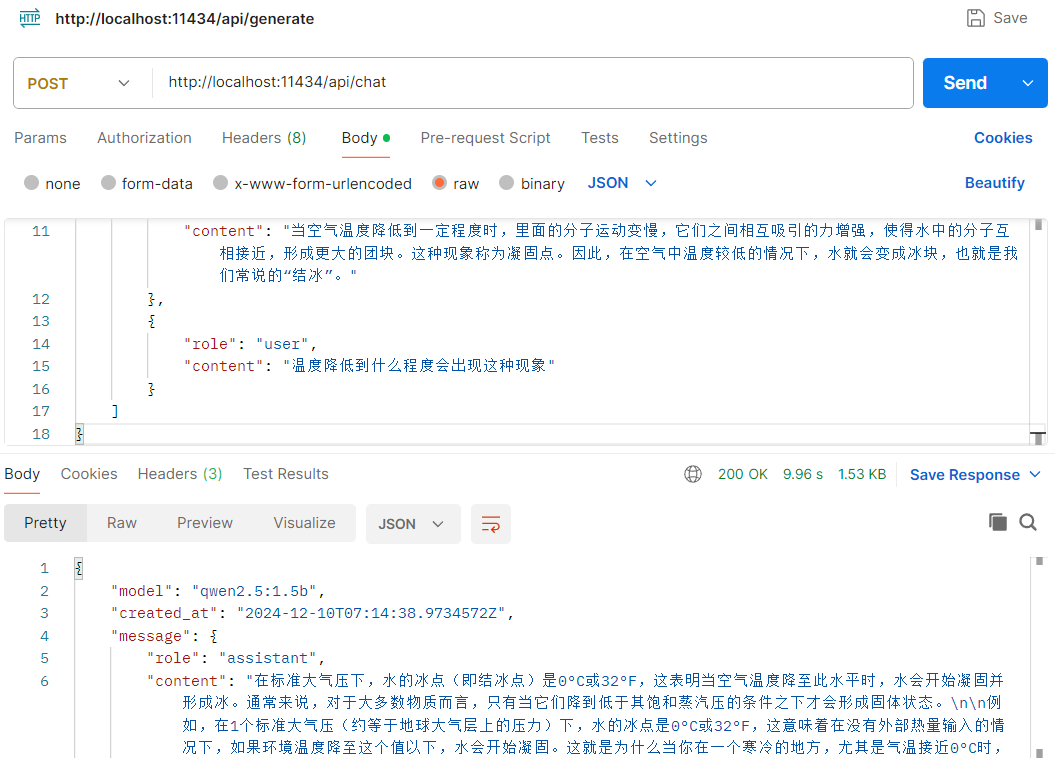
请求体中的messages数组可以包含对话历史,用来保持聊天记忆,示例请求体如下:
{
"model": "qwen2.5:1.5b",
"stream": false,
"messages": [
{
"role": "user",
"content": "为什么天气冷的时候水会结冰"
},
{
"role": "assistant",
"content": "当空气温度降低到一定程度时,里面的分子运动变慢,它们之间相互吸引的力增强,使得水中的分子互相接近,形成更大的团块。这种现象称为凝固点。因此,在空气中温度较低的情况下,水就会变成冰块,也就是我们常说的“结冰”。"
},
{
"role": "user",
"content": "温度降低到什么程度会出现这种现象"
}
]
}