 准备好训练所需的图片后,我们就可以开始写程序了。首先引入所需的库。
准备好训练所需的图片后,我们就可以开始写程序了。首先引入所需的库。
import zipfile import random import tensorflow as tf from tensorflow.keras.optimizers import RMSprop from tensorflow.keras.preprocessing.image import ImageDataGenerator from shutil import copyfile import os查看一下准备好的数据集里猫和狗的图片各有多少张。
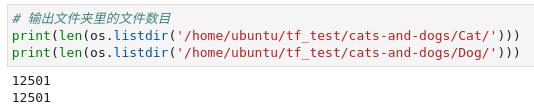
# 输出文件夹里的文件数目
print(len(os.listdir('/home/ubuntu/tf_test/cats-and-dogs/Cat/')))
print(len(os.listdir('/home/ubuntu/tf_test/cats-and-dogs/Dog/')))
 我们需要对上述的猫、狗图片进行进一步划分,将猫、狗图片分别划分为训练部分和测试部分,所以我们这里要先建立用于存放的文件夹。
我们需要对上述的猫、狗图片进行进一步划分,将猫、狗图片分别划分为训练部分和测试部分,所以我们这里要先建立用于存放的文件夹。
# 创建文件夹
try:
os.mkdir('/home/ubuntu/tf_test/cats-and-dogs/training')
os.mkdir('/home/ubuntu/tf_test/cats-and-dogs/testing')
os.mkdir('/home/ubuntu/tf_test/cats-and-dogs/training/cats')
os.mkdir('/home/ubuntu/tf_test/cats-and-dogs/training/dogs')
os.mkdir('/home/ubuntu/tf_test/cats-and-dogs/testing/cats')
os.mkdir('/home/ubuntu/tf_test/cats-and-dogs/testing/dogs')
except OSError:
pass
下面的代码就是将原有的猫、狗图片划分为训练集和测试集,并跳过大小为0的文件,划分比例是猫、狗图片的各90%为训练集,各10%为测试集。
# 分割猫、狗的训练集和测试集
import os
import shutil
def split_data(SOURCE, TRAINING, TESTING, SPLIT_SIZE): # 跳过0长度的文件
files = []
for filename in os.listdir(SOURCE):
file = SOURCE + filename
if os.path.getsize(file) > 0:
files.append(filename)
else:
print(filename + " is zero length, so ignoring.")
training_length = int(len(files) * SPLIT_SIZE)
testing_length = int(len(files) - training_length)
shuffled_set = random.sample(files, len(files))
training_set = shuffled_set[0:training_length]
testing_set = shuffled_set[-testing_length:]
for filename in training_set:
this_file = SOURCE + filename
destination = TRAINING + filename
copyfile(this_file, destination)
for filename in testing_set:
this_file = SOURCE + filename
destination = TESTING + filename
copyfile(this_file, destination)
CAT_SOURCE_DIR = "/home/ubuntu/tf_test/cats-and-dogs/Cat/"
TRAINING_CATS_DIR = "/home/ubuntu/tf_test/cats-and-dogs/training/cats/"
TESTING_CATS_DIR = "/home/ubuntu/tf_test/cats-and-dogs/testing/cats/"
DOG_SOURCE_DIR = "/home/ubuntu/tf_test/cats-and-dogs/Dog/"
TRAINING_DOGS_DIR = "/home/ubuntu/tf_test/cats-and-dogs/training/dogs/"
TESTING_DOGS_DIR = "/home/ubuntu/tf_test/cats-and-dogs/testing/dogs/"
def create_dir(file_dir):
if os.path.exists(file_dir):
print('true')
shutil.rmtree(file_dir) # 删除再建立
os.makedirs(file_dir)
else:
os.makedirs(file_dir)
create_dir(TRAINING_CATS_DIR)
create_dir(TESTING_CATS_DIR)
create_dir(TRAINING_DOGS_DIR)
create_dir(TESTING_CATS_DIR)
split_size = .9
split_data(CAT_SOURCE_DIR, TRAINING_CATS_DIR, TESTING_CATS_DIR, split_size)
split_data(DOG_SOURCE_DIR, TRAINING_DOGS_DIR, TESTING_DOGS_DIR, split_size)
划分训练集和测试集后我们再来查看一下各个文件夹中的文件个数。
# 打印各个文件夹里的文件个数
print(len(os.listdir('/home/ubuntu/tf_test/cats-and-dogs/training/cats')))
print(len(os.listdir('/home/ubuntu/tf_test/cats-and-dogs/training/dogs')))
print(len(os.listdir('/home/ubuntu/tf_test/cats-and-dogs/testing/cats')))
print(len(os.listdir('/home/ubuntu/tf_test/cats-and-dogs/testing/dogs')))
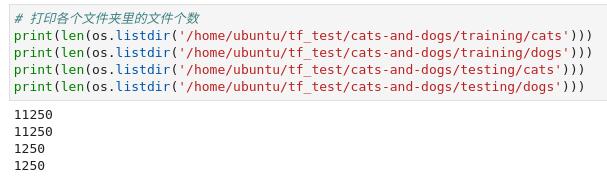 可以看到程序已经按照我们的要求划分好了训练集和测试集。
接下来我们就来搭建神经网络,这里有3个卷积层和3个最大池化层,激活函数使用ReLU,卷积和池化后输入全连接层。
这里使用Conv2D创建一个卷积核对输入数据进行卷积计算。
使用MaxPooling2D对卷积层输出的空间进行最大池化。
使用Flatten将输入该层级的数据压平,Dense则提供了全连接的标准神经网络。
设计完神经网络后,我们用compile对神经网络模型进行编译,生成可以训练的模型,并在编译时指定好损失函数(loss)、优化器(optimizer)和模型评价标准(metrics)。
这一部分的具体代码如下:
可以看到程序已经按照我们的要求划分好了训练集和测试集。
接下来我们就来搭建神经网络,这里有3个卷积层和3个最大池化层,激活函数使用ReLU,卷积和池化后输入全连接层。
这里使用Conv2D创建一个卷积核对输入数据进行卷积计算。
使用MaxPooling2D对卷积层输出的空间进行最大池化。
使用Flatten将输入该层级的数据压平,Dense则提供了全连接的标准神经网络。
设计完神经网络后,我们用compile对神经网络模型进行编译,生成可以训练的模型,并在编译时指定好损失函数(loss)、优化器(optimizer)和模型评价标准(metrics)。
这一部分的具体代码如下:
# 搭建网络结构
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译网络模型
model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])
为了更快更好的训练模型,我们还需要对数据进行预处理,具体操作如下:
# 数据预处理,batch_size代表一次训练所选取的样本数,batch_size=100即每批样本100个 TRAINING_DIR = "/home/ubuntu/tf_test/cats-and-dogs/training/" train_datagen = ImageDataGenerator(rescale=1.0/255.) train_generator = train_datagen.flow_from_directory(TRAINING_DIR,batch_size=100,class_mode='binary',target_size=(150, 150)) VALIDATION_DIR = "/home/ubuntu/tf_test/cats-and-dogs/testing/" validation_datagen = ImageDataGenerator(rescale=1.0/255.) validation_generator = validation_datagen.flow_from_directory(VALIDATION_DIR,batch_size=100,class_mode='binary',target_size=(150, 150))准备工作都做好后,我们就要开始训练模型了。我们调用fit方法来训练模型,为了缩短训练时间,这里只训练了2轮,大家可以根据实际情况进行修改。
# fit就是拟合,epochs=2代表2轮,verbose代表是否记录每次训练的日志 history = model.fit(train_generator,epochs=2,verbose=1,validation_data=validation_generator)
 训练完成后,我们可以分析训练日志,通过图表直观的查看准确度和损失的变化。
训练完成后,我们可以分析训练日志,通过图表直观的查看准确度和损失的变化。
# 分析日志,输出性能曲线,看一下训练样本和测试样本的准确度
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc))
plt.plot(epochs, acc, 'r', "Training Accuracy")
plt.plot(epochs, val_acc, 'b', "Validation Accuracy")
plt.title('Training and validation accuracy')
plt.figure()
plt.plot(epochs, loss, 'r', "Training Loss")
plt.plot(epochs, val_loss, 'b', "Validation Loss")
plt.figure()
 现在我们可以随便找一张图片,使用模型进行预测,判断图片内的动物是猫还是狗。
现在我们可以随便找一张图片,使用模型进行预测,判断图片内的动物是猫还是狗。
# 输入新的图片,经过预处理后,输入到预处理的网络中,预测这个图片是狗还是猫
import numpy as np
from keras.preprocessing import image
import matplotlib.pyplot as plt
path = '/home/ubuntu/下载/test1.jpg'
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
images=images/255
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0]>0.5:
print("这是狗")
else:
print("这是猫")
plt.imshow(img) # 显示图片
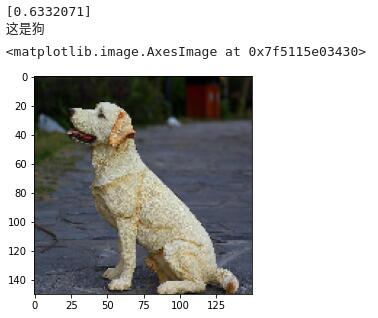 最后,使用save方法将训练完成的神经网络模型保存为H5格式的模型文件,以便下次调用。
最后,使用save方法将训练完成的神经网络模型保存为H5格式的模型文件,以便下次调用。
filename='/home/ubuntu/tf_test/cats-and-dogs/model.h5'
model.save(filename)
print("保存模型为model.h5")
自此,我们已经成功使用TensorFlow2搭建了一个解决图像二分类问题的卷积神经网络,并利用训练好的模型成功对新图像进行了分类。
参考资料:TensorFlow 入门实操课程 - 中国大学MOOC 数据集下载:点击跳转